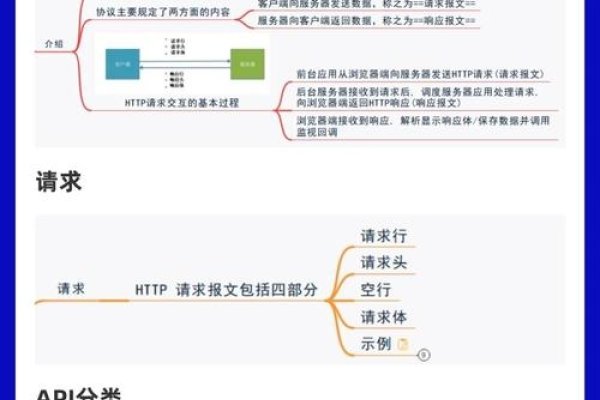
要抓取网站源码,无需多余内容,可利用浏览器开发者工具进行查看,在浏览器中打开想要查看源码的网页,右键点击页面,选择“检查”或“审查元素”等选项,即可进入开发者工具界面,在此界面中,可以查看网页的HTML、CSS和JavaScript等代码,还可以使用一些网络抓包工具来获取网站数据包中的源码信息,这些方法无需额外软件或插件,简单易行。
在互联网时代,网站源码的获取对于许多用户来说具有重要价值,无论是为了学习、研究、修改或二次开发,了解如何抓取网站源码都是一项必备的技能,本文将详细介绍如何抓取网站源码的步骤和注意事项。
准备工作
- 确定抓取目的:在开始抓取网站源码之前,首先要明确自己的目的,是为了学习、研究还是其他用途?这有助于你选择合适的抓取方法和工具。
- 了解相关法律法规:在抓取网站源码时,要遵守相关法律法规,尊重网站版权和隐私,确保你的行为合法合规。
抓取网站源码的方法
- 使用浏览器开发者工具:大多数现代浏览器都提供了开发者工具,可以通过这些工具查看和复制网页的源码,具体步骤如下:
(1)打开你想要抓取源码的网站。
(2)右键点击页面,选择“检查”或“开发者工具”。
(3)在打开的开发者工具中,可以看到页面的HTML、CSS和JavaScript等源码。
(4)选择需要抓取的代码部分,右键复制即可。 - 使用网络抓包工具:如果你需要抓取网站的后端数据或API接口,可以使用网络抓包工具进行抓取,常见的网络抓包工具有Wireshark、Fiddler等,这些工具可以捕获网站与服务器之间的通信数据包,从而获取网站的源码。
- 使用爬虫程序:对于需要批量抓取网站源码的情况,可以使用爬虫程序进行抓取,爬虫程序可以根据设定的规则自动访问网站并提取所需数据,常见的爬虫程序有Python的Scrapy、BeautifulSoup等,需要注意的是,使用爬虫程序时要遵守网站的robots协议和法律法规,避免对网站造成不良影响。
注意事项
- 尊重版权:在抓取网站源码时,要尊重网站的版权和隐私,不要将抓取的源码用于非法用途或侵犯他人权益的行为。
- 遵守法律法规:在抓取网站源码时,要遵守相关法律法规和网站的规定,不要进行恶意攻击或破坏网站的行为。
- 注意网站反爬虫策略:一些网站会采取反爬虫策略来防止恶意抓取,如果你发现自己的爬虫程序被网站封禁或无法正常工作,可以尝试调整爬虫策略或等待一段时间后再尝试。
本文介绍了如何抓取网站源码的步骤和注意事项,通过使用浏览器开发者工具、网络抓包工具或爬虫程序等方法,你可以轻松地获取网站的源码,但需要注意的是,在抓取网站源码时,要遵守相关法律法规和网站的规定,尊重网站的版权和隐私。