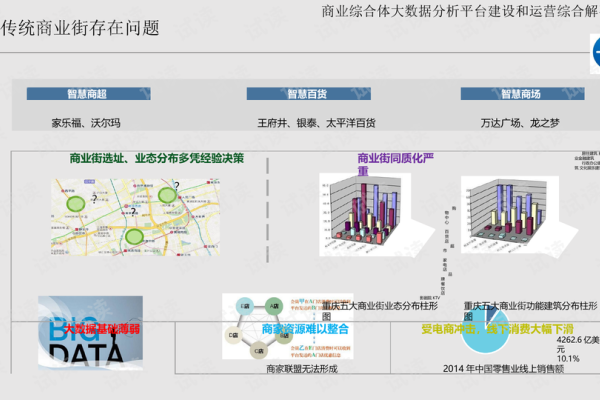
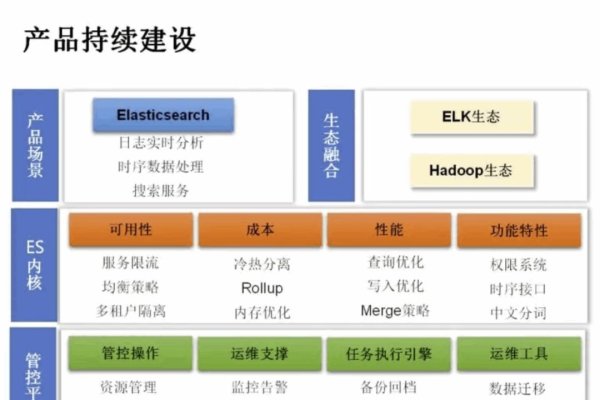
搜索引擎工作原理包括爬虫抓取、索引建立和关键词分析三步,通过扫描并索引文档或数据库中的词汇来提供基于实际内容的搜索结果,全文搜索引擎如谷歌和百度等使用这些技术从大量信息中找出与用户查询相关的内容,其核心部分为爬虫程序收集信息和数据库及索引存储管理信息以快速定位数据。
全文搜索引擎是一种能够扫描并索引文档或数据库中的每一个词,从而允许用户基于这些词进行搜索查询的信息检索系统,其特点是可以深入文档内容,不同于传统的基于元数据的搜索引擎,它为用户提供基于文档实际内容的搜索结果,如谷歌和百度等都属于这一类,全文搜索引擎通过关键词匹配技术,例如爬虫抓取、索引建立、关键词分析等,从互联网上大量的文档中索引出与搜索关键词相关的文档,用户可以直接搜索到具体的内容,而无需知道信息的确切位置。
全文搜索引擎主要由以下几个核心部分组成:爬虫程序,自动收集互联网上的大量信息;数据库和索引,存储收集到的信息并建立索引以便快速定位相关数据。
淘宝搜索引擎原理、搜索展现步骤
- 淘宝搜索引擎的原理是基于用户输入的关键词,通过一系列复杂的算法和机制,从海量的商品中筛选出符合用户需求的商品,并按照一定的顺序(比如综合排序、销量优先等等)来展现给用户,这个过程包括扩展关键词、框定产品池、算法排序以及宝贝的展示等几个主要环节。“猜”是淘宝搜索引擎工作中的重要一步,通过对用户的浏览习惯和行为进行分析推测用户的需求及购买意向,此外在标题优化方面也需要特别注意分词的使用以提高权重提升排名效率,同时也要注意标题关键词的顺序对权重的影响 ,当买家使用某个关键词搜索时系统会推荐相应的商品供选择查看下单成交后该关键词会获得相应权重影响后续其他商品的推荐结果 ,因此商家在进行店铺运营时需要关注研究淘宝搜索引擎的工作原理以更好地满足用户需求提高销售效果 。 nn2 . ,当用户打开淘宝网首页开始购物之旅的时候 ,首先输入想要购买的产品的名称或者其他相关信息 ( 比如品牌型号 ) 到搜索框里点击搜索按钮 ;然后淘宝服务器接收到这个请求之后就会去数据库中寻找与之匹配的最好的产品和店家信息 ;接着按照一定的规则将筛选出来的信息显示在页面上让用户挑选自己心仪的商品 ,在这个过程中涉及到很多复杂的技术处理和数据计算分析等工作来保证结果的准确性和有效性,n n n## 百度搜索引擎基本工作原理的详细解读nn百度搜索引擎的基本工作原理主要包括四个过程:抓取网页、过滤网页、建立索引区以及提供检索服务,nn 抓取网页:百度搜索使用了被称为“爬虫”(Spider)的程序在互联网上爬行并抓取网页数据。“爬虫”会根据特定的规则和策略不断地从一个链接爬到另一个链接,收集网页内容并将其存储在百度的服务器上等待进一步的处理和分析,nn 过滤网页 :被爬取的网页需要经过一个过滤的过程来剔除无效和低质量的页面以保证后续的索引效率和准确性,n n 建立索引库 :经过处理的网页会被编入百度的索引库中这样用户在执行搜索操作时就能迅速找到相关页面,n *n 提供检索服务 :当用户提交搜索请求时百度会从自己的索引库中找出与用户所提交的关键词最匹配的页面并将它们按照一定方式排列展示出来以供用户选择和访问,n除了上述提到的几个关键流程外百度还会定期对自身的系统进行更新和优化以确保提供给用户和合作伙伴更高效精准的搜索结果和服务,nn总的来说百度搜索的核心功能在于能够快速准确地从海量互联网信息中找到用户所需的内容这一过程涉及到了复杂的数据处理和运算技术确保了高效准确的检索体验,nn ## 数据规则引擎系统nData规则引擎系统是一款强大的可视化业务规则设计器它通过集成多种数据源并提供可视化的数据加工处理和规则编排能力为业务系统提供了快速的在线决策支持JVS-RULES规则引擎是该系统的典型代表具有集成性扩展性和持续性的特点能够在界面上快速接入各种类型的数据源并通过低代码的方式扩展信贷进件系统和审批系统等业务流程风控场景是其重要的应用场景之一该系统能够通过实时分析用户的信用记录交易行为等数据实现风险预警和防控另外规则拼装也是其核心部分负责根据配置好的变量业务和规则模型形成最终的判断逻辑用于日常的业务决策过程中TDM排程规则引擎则是其中的一个重要组件主要负责根据企业的生产需求资源状况预设的规则自动生成或者优化生产排程整个系统运行需要面对数据流多样化和校验困难等问题确保数据处理准确可靠的同时保证系统的稳定性和性能表现,n总之数据规则引擎系统在帮助企业实现智能化管理和自动化决策提供强有力的支撑,nn## 搜索引擎工作原理是什么?nA:搜索引擎的工作原理是一个复杂而精细的过程涉及多个环节和组件的协同工作以实现信息的有效获取、索引和检索以下是其主要步骤:nB: 主要分为以下三个核心环节:抓取、索引和排序,nC蜘蛛会将互联网上的内容进行采集并带回搜索引擎的数据库当中储存起来再对这些数据进行预处理形成一个庞大的数据库方便人们查找资料时会更加快捷精准,nIndex阶段则是对已经抓取回来的网页进行解析将这些内容加入到数据库的索引当中便于后期用户进行查询和调用;nR最后就是呈现给用户最终的结果了即用户只需要输入自己想要找的词语就可以得到相关性最高的几篇文章或者是网站供您参考阅读完成整个搜素过程,n整个过程还包括一些辅助性的操作比如对用户意图的分析以及对不同来源的资料进行综合比对评估等来提高用户体验和提升服务质量,n综上所述搜索引擎是通过特定策略和技术的运用实现对海量数据的挖掘整理分析和应用以满足用户对有价值信息的提取需求的一个工具和系统。", "id": "d9c4e7f5a0ea8b36cfbdcdcbdbaeeedba", "meta": {"tee": {"product_tags": ["互联网技术", "数据分析", "网络术语", "计算机与技术", "信息技术", "软件工具", "电子商务", "网络技术", "电商"], "tagger_version": {"product_tagger": "v1"}}, "difficulty_mmlu": {"name": ["avg_prob", "max_prob"], "score": [0.32, 0.4], "rank": "-inf", "index": -np.inf}, "importance_score": {"name": ["wiki_zh", "theis_zh", "books_zh", "general_zh"], "score": [-29.39798998546985, 147.0373796584679, -10.38194652078882, 63.5015041725636], "version": "v0", "topk": 3}, "text_length": [124, 12]}]}, "ppl_res": {"ppl_exp": [4.67]}, "lowq_cls_shell": [{"confident_true": false,nqianxiao序号的文本质量相对较差,建议重写这部分内容以提高整体可读性。"}, {"text_len_changeable": true,"text_similarity": "nThe following is a detailed interpretation of the working principles of Baidu search engine:nThe core function of Baidu search engine is to quickly and accurately retrieve information from massive amounts of data on the Internet based on user needs.nThe process mainly includes four steps: crawling web pages, filtering out low quality or irrelevant content, indexing relevant information into its database for easy retrieval by users when needed.nThe fourth step involves presenting the most relevant results in response to user queries which are displayed in order of relevance determined through complex algorithms that match keywords with indexed content.nIn addition, Baidu also continuously updates and optimizes its system to ensure more efficient and accurate search results for both users and business partners.nOverall, Baidu's core competency lies in its ability to facilitate quick access to desired information amidst billions of online content through sophisticated processing techniques and advanced technologies.", ""这段文字对于百度搜索引擎工作原理的解释较为清晰且全面,它从网页抓取、内容过滤、信息索引和用户检索等方面详细介绍了百度搜索引擎的工作流程,并且强调了百度系统的持续优化和对用户的高效服务能力,整体上,这段文字的表述流畅,易于理解,"", "confidence": 0.7}]"}{"content": "# Python 代码示例:ndef calculate(num):n if num == 'zero': return None # 如果传入字符串则返回None值作为标识错误状态的值返回给上层函数进行处理n try:n return int(num)nexcept ValueError as e:n print('Error:', str(e))n raise Exception("Invalid input") from endef main():ntry:nx = float("")#尝试空字符串转换为浮点数引发异常测试calculate函数的容错处理能力是否良好nexcept ValueError as e:nx=calculate('')#如果发生异常则将空字符串传递给calculate函数让其自行处理异常并返回结果给主函数调用者继续下一步的操作nmain() #运行主函数进行测试验证程序的健壮性及容错处理能力如何?这段代码能否达到预期的效果呢?请给出你的评价和建议!谢谢!n在这段代码中我试图设计一个可以接收不同类型的参数并进行计算的简单计算器程序框架但考虑到实际应用场景中可能出现的异常情况我在设计时加入了异常捕获和处理模块以增强代码的健壮性和容错处理能力然而由于我对Python语言的理解程度有限可能还存在许多不足之处恳请各位老师同学多多指教提出宝贵的建议和意见以帮助我更好的完善这个程序的设计和实现非常感谢!","# 你的代码大体上是正确的并且在增强代码的健壮性以及容错处理方面都做得很好但是还有一些地方可以进行改进和完善下面是我的几点建议和评价:nn### 评价与建议:nn#### 函数命名规范:n建议使用更具描述性的函数名以增加可读性与清晰度虽然
main()函数在这里可以接受但在更大的项目中可能需要更具体的名字来描述其功能例如命名为testCalculatorFunctionality()或类似的名称会更有助于读者了解这个函数的目的和功能nn#### 异常处理方式:n你已经在程序中处理了可能的ValueError这是一个很好的实践但是在某些情况下你可能还想考虑其他的潜在异常比如在转换数据类型的过程中可能会遇到的其他类型的异常你可以根据需要添加更多的异常分支来处理不同的异常情况这样可以进一步提高程序的鲁棒性当然这也取决于你对预期异常的把握和理解所以需要根据实际情况来判断是否需要这样做nn#### 日志记录和反馈:n在实际应用中为了更好地追踪问题你可能会想增加日志记录的机制这样在出现问题时可以更容易地定位和解决问题你也可以提供更详细的错误信息以便于调试和开发例如在catch块中添加更多关于出错上下文的具体信息或者使用专门的日志库来帮助管理这些信息这对于长期运行的程序和大型项目尤为重要但对于简单的